86
What's the reason for the empty comments, lately?
(discuss.tchncs.de)
I think they're using Widevine DRM. And with DRM they can enforce whatever arbitrary policies they like. They set special restrictions for Linux. I think Amazon set 480p as max, Netflix 720p and YouTube 4k or sth like that. AFAIK it has little to do with technology. It's just a number that the specific company sets in their configuration.
I think this is the answer. They also need to advertise correctly so people feel the need to finance a $70.000 truck instead of buying a small used car for $4.000. Of course with interest and their credit score people will end up paying like double the price anyways.
Another option is to offer crappy versions of the same thing that are more affordable but break earlier. That way you also pay more over the years.
Software. 99% of the time there is some Free Software alternative that either somehow does the job for my personal tasks, or is better anyways.
That is partly correct. Wayland is not based on X.org. There is nothing rewritten, removed or simplified. It's an entirely new design, new code with a different license. And X11 isn't written by a single developer. XFree86 was started by 3 people, got maintained by an incorporated and then became X.org and sponsored by an industry consortium (the X.Org Foundation). Many many people and companies contributed. The rest is correct. It grew too complex and maintenance is a hassle. Wayland simplifies things and is a state of the art approach. Nobody removed features but they started from zero so it took a while to implement all important features. As of today we're almost there and Wayland is close to replacing X11.
You're kind of Robin Hood if you steal software and give the money to FOSS projects. 😄
It will never get recommended. It's bad for the network and bad for your privacy.
They are referencing this paper: LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset from September 30.
The paper itself provides some insight on how people use LLMs and the distribution of the different use-cases.
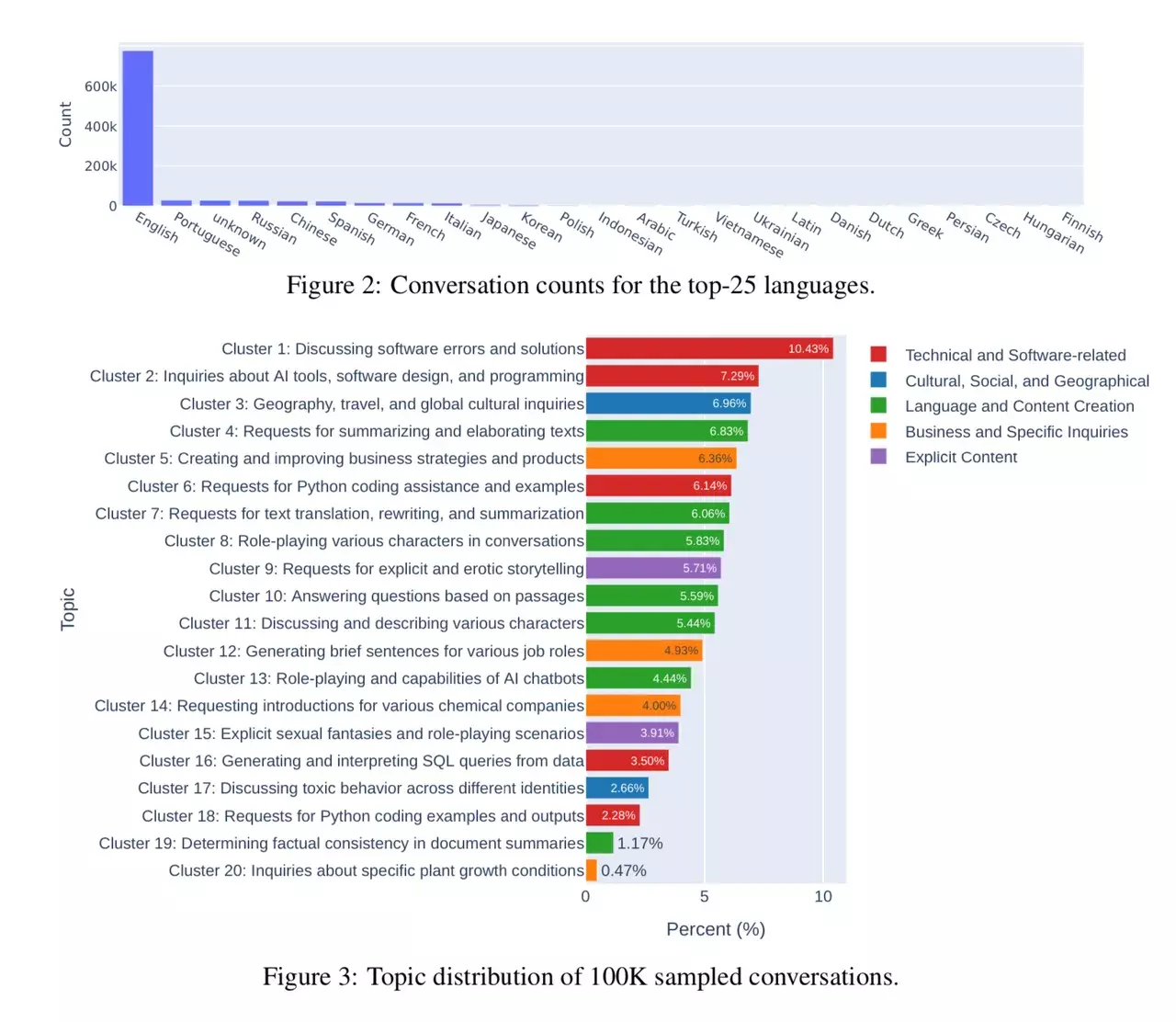
The researchers had a look at conversations with 25 LLMs. Data is collected from 210K unique IP addresses in the wild on their Vicuna demo and Chatbot Arena website.
0.5 showers a day
Interesting. Replika AI, ChatGPT etc crack down on me for doing erotic stories and roleplay text dialogues. And this Clothoff App happily draws child pornography of 14 year olds? Shaking my head...
I wonder why they have no address etc on their website and the app isn't available in any of the proper app-stores.
Obviously police should ask Instagram who blackmails all these girls... Teach them a proper lesson. And then stop this company. Have them fined a few millions for generating and spreading synthetic CP. At least write a letter to their hosting or payment providers.
I think it's written 'tonne'. And you should call it metric tonne if it's not clear from the context.
Wikipedia says:
The tonne is a unit of mass equal to 1000 kilograms. It is a non-SI unit accepted for use with SI. It is also referred to as a metric ton to distinguish it from the non-metric units of the short ton (United States customary units) and the long ton (British imperial units). The official SI unit is the megagram (symbol: Mg), a less common way to express the same amount.
https://en.wikipedia.org/wiki/Tonne
So yes, you can call it a megagramme and you'd be right. But we european people also sometimes do silly stuff and colloquially use wrong things. For example we also say it's 20 degrees celsius outside. And that's not the proper SI unit either. But that's kinda another topic.

If your door opens into the room, use a door wedge. Really cheap and super effective. Close your door and really drive it in. If it slips, try a plastic/rubber one.
Other than that: Listen to the other people. This isn't normal behaviour. And you're the victim of mental abuse here.
Thanks for spreading the word. We get these complaints every few weeks. More people need to be educated and move away from these instances to make the Threadiverse a better place.