thinking about how I was inoculated against part of ai hype bc a big part of my social circle in undergrad consisted of natural language processing people. they wanted to work at places with names like "OpenAI" and "google deepmind," their program was more or less a cognitive science program, but I never once heard any of them express even the slightest suspicion that LLMs of all things were progressing toward intelligence. it would have been a nonsequiter.
also from their pov the statistical approach to machine learning was defined by abandoning the attempt to externalize the meaning of text. the cliche they used to refer to this was "the meaning of a word is the context in which it occurs."
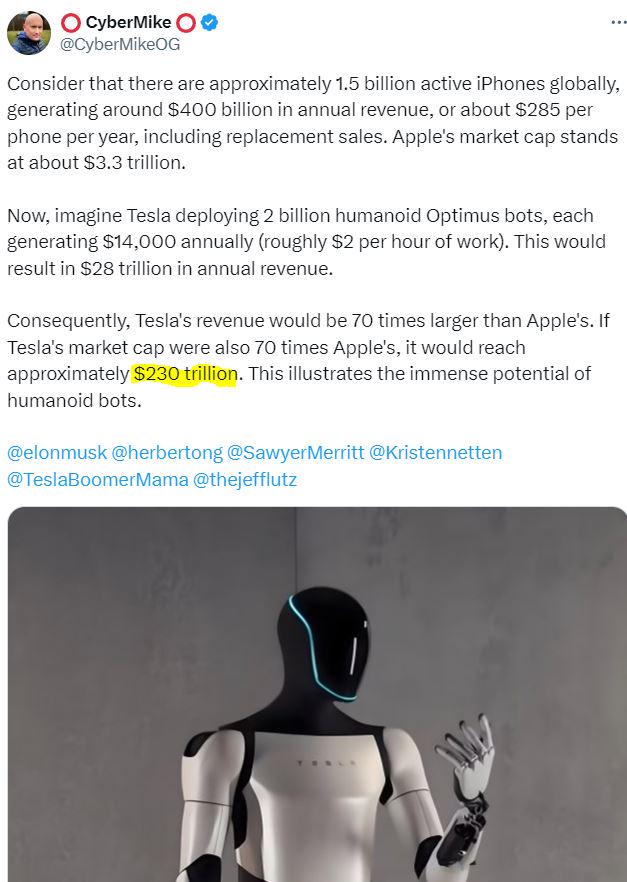
finding out that some prestigious ai researchers are all about being pilled on immanetizating agi was such a swerve for me. it's like if you were to find out that michio kaku has just won his fourth consecutive nobel prize in physics