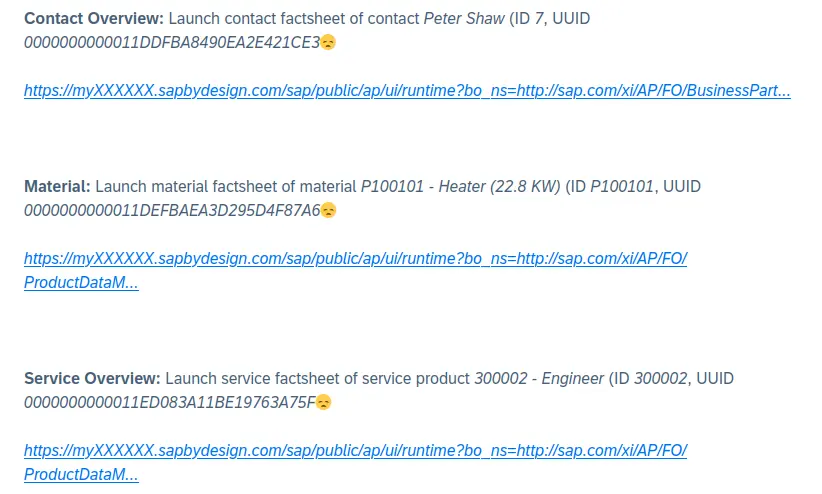
Contact Overview: Launch contact factsheet of contact Peter Shaw (ID 7, UUID 0000000000011DDFBA8490EA2E421CE3😞
https://myXXXXXX.sapbydesign.com/sap/public/ap/ui/runtime?bo_ns=http://sap.com/xi/AP/FO/BusinessPart...
Material: Launch material factsheet of material P100101 - Heater (22.8 KW) (ID P100101, UUID 0000000000011DEFBAEA3D295D4F87A6😞
https://myXXXXXX.sapbydesign.com/sap/public/ap/ui/runtime?bo_ns=http://sap.com/xi/AP/FO/ProductDataM...
Service Overview: Launch service factsheet of service product 300002 - Engineer (ID 300002, UUID 0000000000011ED083A11BE19763A75F😞
https://myXXXXXX.sapbydesign.com/sap/public/ap/ui/runtime?bo_ns=http://sap.com/xi/AP/FO/ProductDataM...