1
Free Open-Source Artificial Intelligence
4776 readers
1 users here now
Welcome to Free Open-Source Artificial Intelligence!
We are a community dedicated to forwarding the availability and access to:
Free Open Source Artificial Intelligence (F.O.S.A.I.)
More AI Communities
LLM Leaderboards
Developer Resources
GitHub Projects
FOSAI Time Capsule
- The Internet is Healing
- General Resources
- FOSAI Welcome Message
- FOSAI Crash Course
- FOSAI Nexus Resource Hub
- FOSAI LLM Guide
founded 3 years ago
MODERATORS
2
3
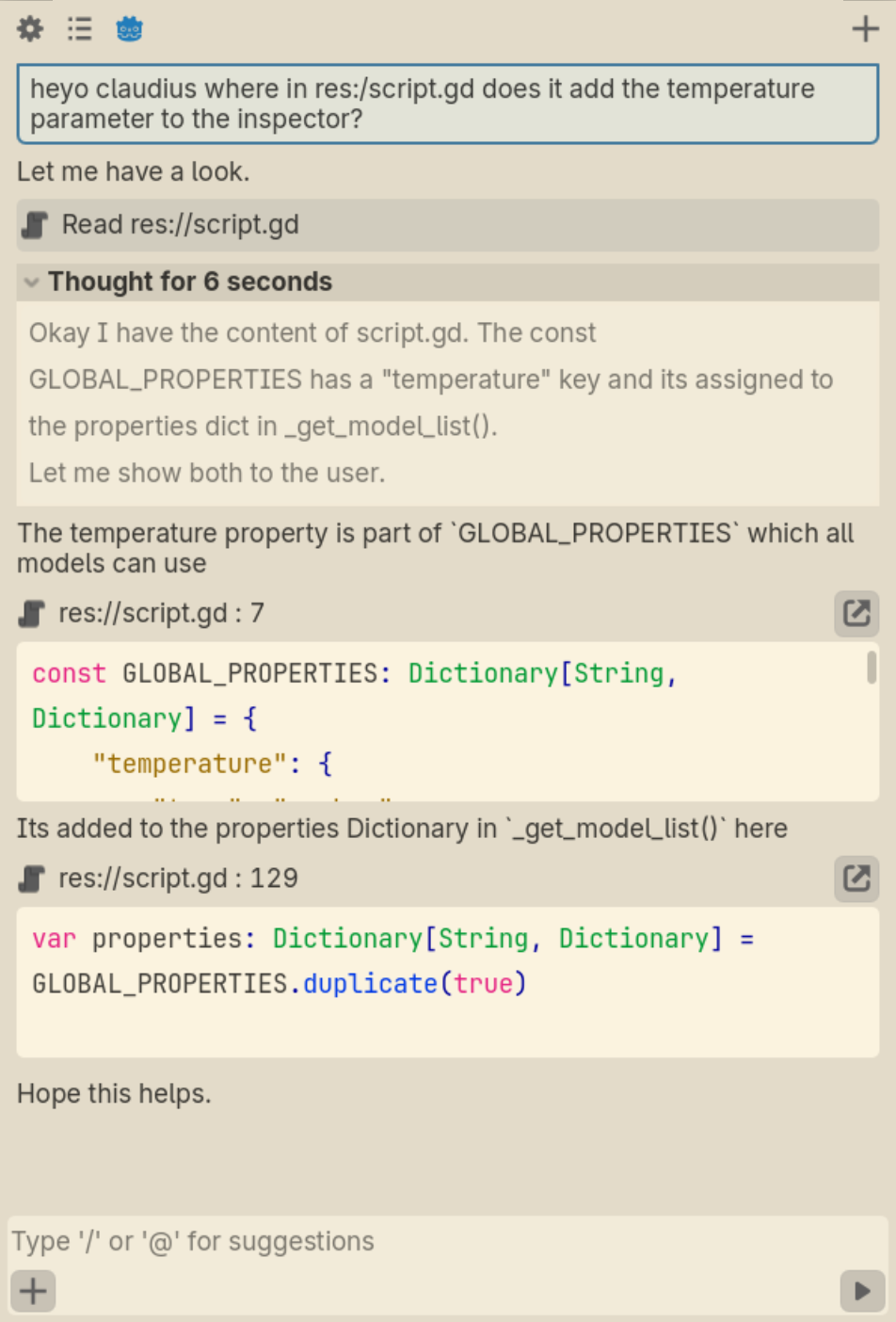
i only really made this so i can link to it on this post on my comment. whatever-
Explanation Time! ⏱
the idea here is that those "code blocks" aren't regular code blocks, but a special syntax which the LM writes so that the UI can present that as verifiable "hyperlinks" with exact text to the actual source.
so here, the LM specified exactly which lines it wants to highlight.
meaning: its not hallucinating, and if it is, you notice it because the highlighting is wrong or doesnt match at all.
we essentially use the LM as a "highlighter" rather than a regurgitator, making mistakes obvious and correct answers immediately verifiably correct, cuz u can see the source.
explanation done-
i like mockups. and godot. so here we are.
this uses the solarized theme which looks somewhat close to the claude theme they use. somewhat close.
whatever something something ai bad or whatever, is this what u need to hear? sigh
i hope u have a nice day <3
this is very much a post i first posted on the Qwen community but then i decided that this stuff doesnt belong on blahaj zone and moved it here... oh well.
4
5
6
7
8
9
Memory is the most marketed and least delivered feature in the AI companion space. Most platforms claim to remember you but either reset between sessions or just pull from a profile you filled in manually. After two years of testing the ones that actually carry real conversational context across weeks are rare. Just published a full breakdown of which platforms actually deliver on this versus which ones are just marketing: medium.com/@companaya/nomi-ai-review-2026-is-it-worth-it-tested-c91811dcb24a

10
11
12
13
14
15
16
17
18
1
cross-posted from: https://lemmy.world/post/45721951
cross-posted from: https://lemmy.world/post/45721900
cross-posted from: https://lemmy.world/post/45721589
Hi All, It has been while,
Dograh is an open-source, self-hostable voice AI agent platform. Think n8n but for phone calls. Visual workflow builder, inbound and outbound calling, bring your own LLM, STT, and TTS.
GitHub: https://github.com/dograh-hq/dograh
Setup
one command with Docker, about 2 minutes. No signup or API keys needed to get started:
What is new
Pre-call data fetch. Hit your CRM, ERP, or any HTTP endpoint during call setup and inject the response into your prompts. The agent greets the caller by name, references their account status, skips the "can I get your customer ID" step. Configure a POST endpoint in the Start Call node - API key, bearer, basic, or custom header auth supported. 10-second timeout; if the endpoint fails, the call continues without the extra context. Reference fetched values anywhere in prompts with {{customer_name}} syntax.
Pre-recorded voice mixing. Drop in actual human recordings for the predictable parts - greetings, confirmations, hold messages - and let TTS handle only what needs to be dynamic. The greeting sounds human because it is. Latency goes down, TTS costs go down.
Speech-to-speech via Gemini 3.1 Flash Live. One single streaming connection replaces the separate STT, LLM, and TTS hops. Turn response latency drops noticeably and the conversations feel more natural.
Post-call QA with sentiment analysis and miscommunication detection. Full per-turn call traces via Langfuse.
Tool calls, knowledge base, variable extraction are all there too.
What is coming
Real-time noise separation for live call streams - still the thing I most want to solve after last week's thread. BSD-2 licensed.
GitHub: https://github.com/dograh-hq/dograh
Special thanks to this community that supported me with my last post ❤️
Happy to get feedback and contributors. A star would mean a lot

19
hey there,
There is always a temptation to add "something AI" in new tools. Especially to tools that are somehow related to developer productivity.
At the same time I wanted to avoid this temptation with Voiden. So there is currently nothing screaming "AI" in it even though I can potentially see many many use cases.
This is also one of the main reasons I think that a plugin architecture is best. What was actually in my mind is that not adding AI is ok for now and the community will start coming up and building AI plugins. For example creating docs from specs and vice versa.
Any other use cases you can think that could be applicable to a tool like this? (Dev Tool with executable markdown files for API specs, tests and docs). The first plugins we shipped were more around methods (grpc, graph ql, web sockets etc etc).
repo: https://github.com/VoidenHQ/feedback

20
21
Small/fast model with MIT license for local use.
Benchmarks look good for the size. But IMO these smaller models aren’t consistent enough to live up to their promises.

22
23
24
25

view more: next ›