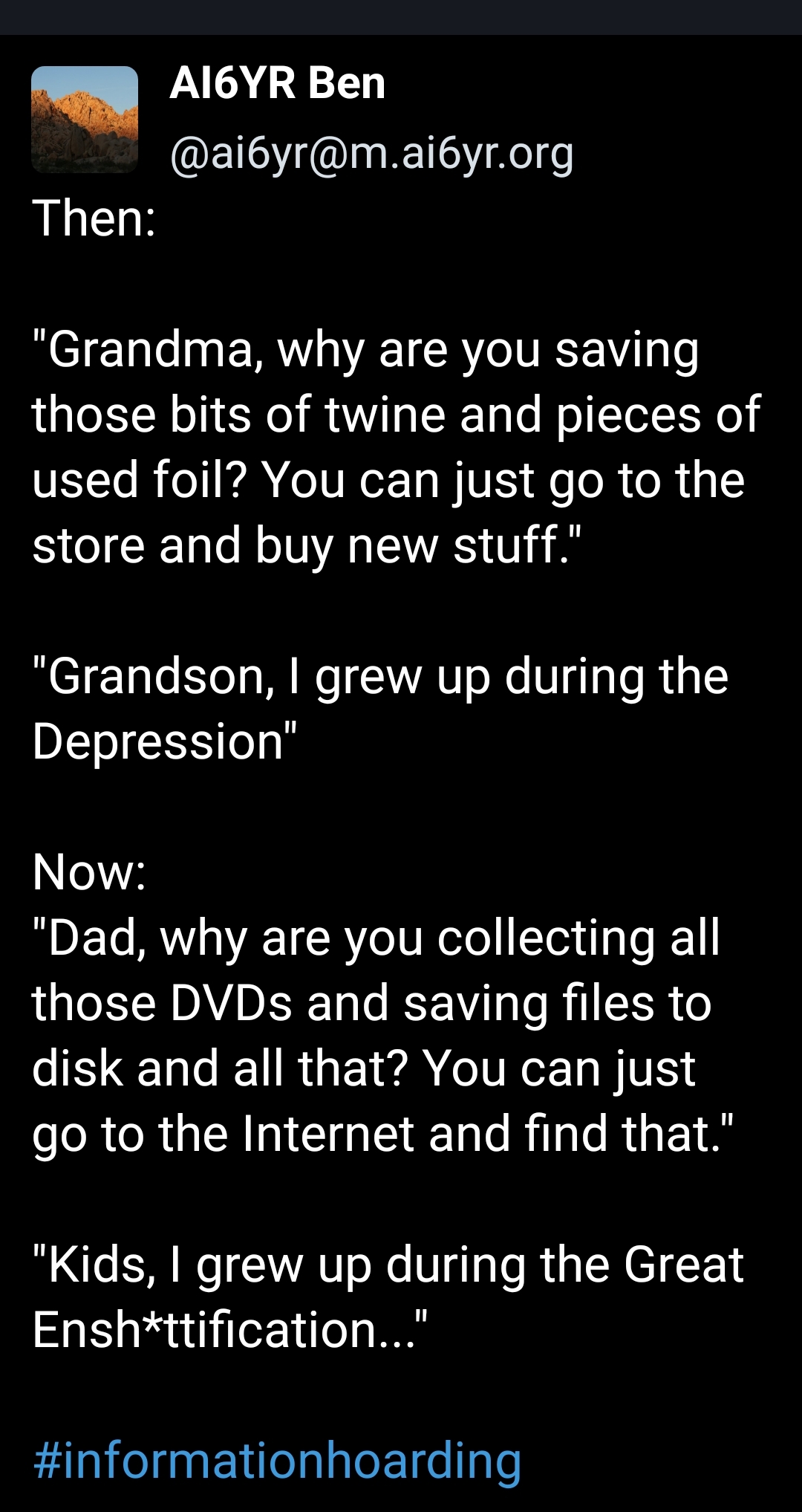
26
I'm celebrating my datahoarding problem.

Who are we?
We are digital librarians. Among us are represented the various reasons to keep data -- legal requirements, competitive requirements, uncertainty of permanence of cloud services, distaste for transmitting your data externally (e.g. government or corporate espionage), cultural and familial archivists, internet collapse preppers, and people who do it themselves so they're sure it's done right. Everyone has their reasons for curating the data they have decided to keep (either forever or For A Damn Long Time). Along the way we have sought out like-minded individuals to exchange strategies, war stories, and cautionary tales of failures.
We are one. We are legion. And we're trying really hard not to forget.
-- 5-4-3-2-1-bang from this thread
cross-posted from: https://lemmy.world/post/17689141
I'll just save them in this folder so that I can totally come back later and read them.

cross-posted from: https://slrpnk.net/post/10273849
Vimms Lair is getting removal notices from Nintendo etc. We need someone to help make a rom pack archive can you help?
Vimms lair is starting to remove many roms that are being requested to be removed by Nintendo etc. soon many original roms, hacks, and translations will be lost forever. Can any of you help make archive torrents of roms from vimms lair and cdromance? They have hacks and translations that dont exist elsewhere and will probably be removed soon with ios emulation and retro handhelds bringing so much attention to roms and these sites