this post was submitted on 13 Oct 2023
38 points (85.2% liked)
Linux
58885 readers
318 users here now
From Wikipedia, the free encyclopedia
Linux is a family of open source Unix-like operating systems based on the Linux kernel, an operating system kernel first released on September 17, 1991 by Linus Torvalds. Linux is typically packaged in a Linux distribution (or distro for short).
Distributions include the Linux kernel and supporting system software and libraries, many of which are provided by the GNU Project. Many Linux distributions use the word "Linux" in their name, but the Free Software Foundation uses the name GNU/Linux to emphasize the importance of GNU software, causing some controversy.
Rules
- Posts must be relevant to operating systems running the Linux kernel. GNU/Linux or otherwise.
- No misinformation
- No NSFW content
- No hate speech, bigotry, etc
Related Communities
Community icon by Alpár-Etele Méder, licensed under CC BY 3.0
founded 6 years ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
Beats me. I just started my windows single gpu passthrough vm and it froze so i rebooted and arch went into emergency mode. The ssd just wont mount. I had to remove it from fstab to boot
I don't think it actually corrupted the SSD, perhaps a module is missing or such, and that's why it goes into emergency mode. Have you tried mounting the drive from say, a live usb?
Yes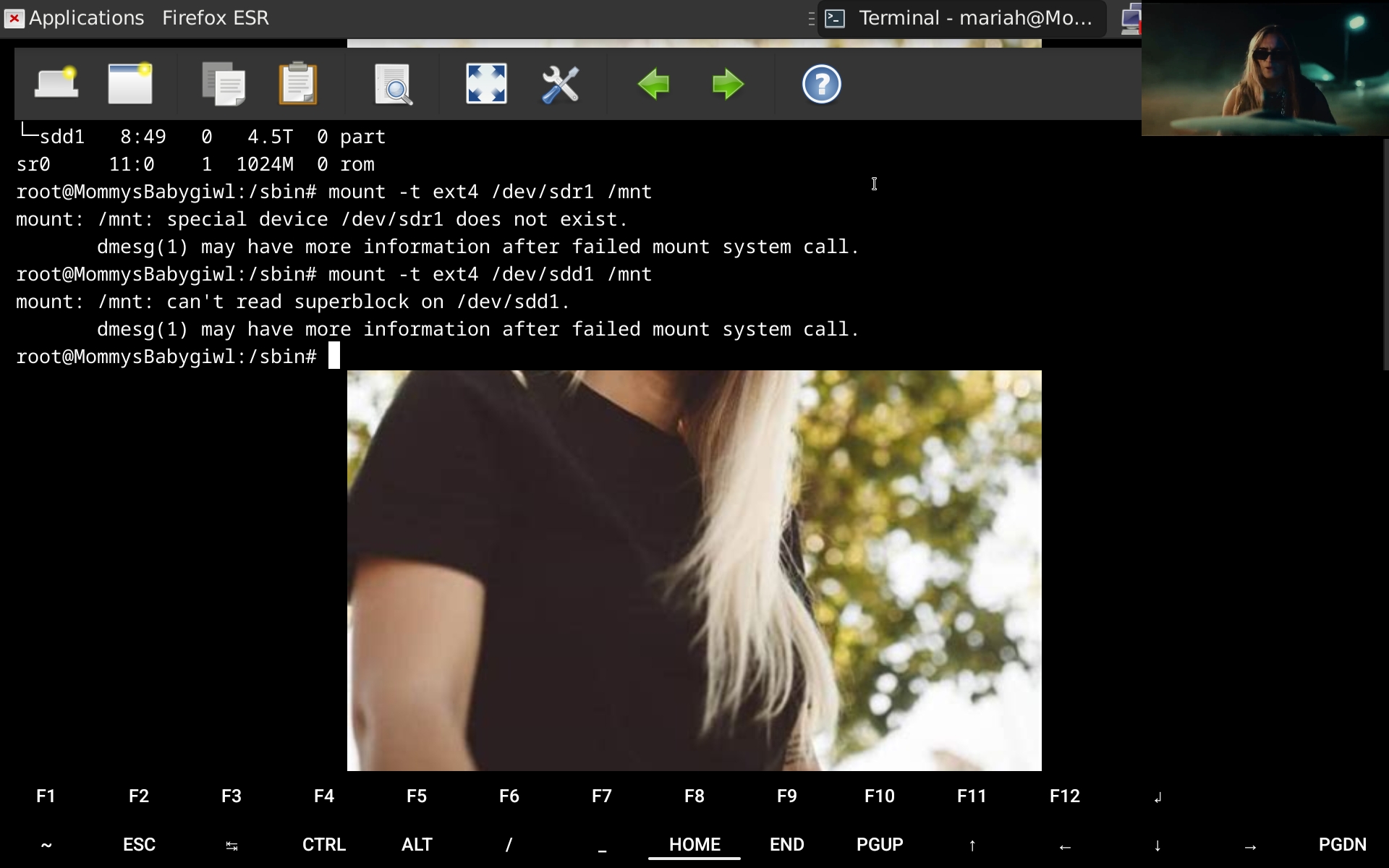 If i can get it working ill be so happy as i have 4000 music videos
If i can get it working ill be so happy as i have 4000 music videos
Arch will go into emergency mode whenever it can't mount a volume in fstab on boot. If the drive is formatted as NTFS, I've had this exact problem. I think it has to do with windows marking the drive as dirty. I didn't bother figuring out what the problem was, I just stopped trying to mount an NTFS drive on boot. Maybe you'd have better luck using the ntfs-3g driver?
Its ext4
Can you see the drive in Debian? Like, does it show up in
lsblkoutput, which doesn't rely on there being anything on the drive? If not, it may have failed. Like, not something that Arch did.Yes
If the partition in question is /dev/sdd1, what does
fsck /dev/sdd1give?Also, you shouldn't need to specify the fs type to
mount, as it'll auto-detect it./usr/sbin/fsck: 1: Syntax error: "(" unexpected
looks puzzled
/usr/sbin/fsckshould be an executable. On my Debian Trixie system, it is. That sounds like it's a script, and whatever interpreter is specified to run it by the shebang line at the top of the file doesn't like the file's syntax. I wouldn't think that any Linux distro would replace that binary with a script, as it's something that has to run when almost everything else is broken.On my system, I get:
Do you get anything like that?
EDIT: Oh, wait, wait, wait.
/usr/sbin/fsckmight be printing that message itself. I was gonna say thatfsckshouldn't be looking at any files, but the man page lists /etc/fstab as a file that it looks at. Looking atstrace -e openat fsckon my system, it does indeed look at /etc/fstab. Maybe the contents of your /etc/fstab are invalid, have a parenthesis in it. Can you also trygrep '(' /etc/fstaband see what that gives?EDIT2: I don't think that it's an
fsckerror message. When I replace the first line of my fstab with left parens, I get "fsck: /etc/fstab: parse error at line 1 -- ignored", which is a lot more reasonable.Sorry i was using sh. This is the output
Ah, okay, that makes more sense.
On my system, looks like fsck.ext2 is a symlink to e2fsck, which is provided by the e2fsprogs package:
Can you try:
And then run:
Again?
E2fsprogs is installed already
rubs chin
Okay. "error 2 (No such file or directory)" is the error code that
perror()will print when it gets ENOENT.checks
One way you can get that is if you attempt to execute a file that isn't there, or execute or open a symlink that has a target that's missing. Could be that fsck.ext2 is missing or is a symlink, and that the
e2fsckbinary that it points to isn't there.On my system, I get this:
Do you get something like that as well?
If they aren't there, you can force reinstallation of e2fsprogs with
# apt install --reinstall e2fsprogsand if the files are missing, that should add them, but I don't know how one could wind up in a situation where the package database thinks that the package is installed but that the binaries aren't present on a fresh Debian install.I do have it
Okay, though I had an idea as to what should cause that, but no, not it. I deleted my response shortly after posting it, if you already saw it.
Hmm. Well, how about this. It should be possible to run e2fsck directly, and you say that the binary is present. Try:
If it says something about /dev/sdd1 being mounted, then don't go ahead with the scan; you've got the wrong partition in that case.
Attempt to read block from filesystem resulted in short read while trying to open /dev/sdd1 Could this be a zero-length partition?
fsck is probably wrong in guessing that it's a zero-length partition; I would be more-inclined to guess that a read error caused it not to be able to read anything.
That should display the partition table on the drive, as well as the lengths of the partition. My guess is that it'll just show that you have a 4.5TB partition. Probably starts at something like 1MB and ends at something like 4500GB.
Linux was able to read from the drive enough to get at the partition table on it, or the
lsblkoutput you had above in that image wouldn't be able to show the partition.But I'd guess that it's hitting read errors in trying to read from the drive, and that the way that this is percolating up to fsck is fsck asking for N bytes and getting back only the bytes that it could read before it hit the error.
It's maybe not impossible that an invalid partition table could produce that error. And maybe e2fsck is trying to read off the end of the device or something because the filesystem on the partition is messed up, but I'm biased towards to thinking that it's more-likely that the drive is failing.
The first option I'm normally going to take when maybe a hard drive is dying is:
As long as the drive supports SMART, that'll tell you whether the drive thinks that it's failing. That won't catch everything, but if the drive doesn't give itself a clean bill of health, then I wouldn't either.
If the kernel is trying to read data from a drive and seeing errors, it'll probably show up in the kernel log.
Should show you errors in the kernel log from the current boot relating to that drive.
If you don't see any errors there, then I'd be inclined to see whether it's possible to read the contents of the partition and whether that can do so. Something like -- and be very careful not to reverse the "if" (input file) and "of" (output file) parameters here, because
ddcan write to a drive and if typed incorrectly, this can overwrite your drive's contents:That'll just try reading from the beginning of the partition, giving you updates as it goes to let you know how much it's read, and then just dump the data into /dev/null. If it fails to read data at some point, it should bail out way before 4.5TB. Probably don't want to wait for the whole partition to be read, though, because 4.5TB is gonna take a while.
If dd can read the contents of the partition, then I assume that e2fsck should be able to as well.
If dd can read the data, then I'd assume that something is wrong with the filesystem, or at least the data on the partition, and it'd make sense to look at that.
If dd can't read the data, then I'd be inclined to blame hardware (or maybe the partition table), since nothing inside the partition itself, including the filesystem, should be able to make dd fail to read the contents of the partition; dd doesn't actually pay any attention to the data that it's reading.
The commands were fine but dd.
Input/output error means the drive is just dying, irrespective of the software. Software can't do anything about failing hardware, and that's what you ran into.
Probably so, but just to be certain about the partition table not causing it, I'd maybe try running the
ddcommand on /dev/sdd rather than /dev/sdd1. It should be able to read a little more than the attempt to read /dev/sdd1 did. I'm not absolutely certain what happens if a partition table is invalid and has a partition that includes a region extending off the end of the hard drive, and I haven't actually seen a dump of the partition table posted by OP. It might be that an attempt to read a partition that extends off the end of the drive gets exposed to an application as an I/O error.I'm also a little surprised by the lack of kernel log messages. Maybe things have changed, but with all of IDE and SATA internal drives, I always got errors logged with the kernel if I/O failed on a drive, and they always referenced the drive's device name.
I just can't think of much higher level stuff that would cause I/O errors while trying to read at a partition level, though.
And a failing drive could also explain the freeze in Arch, the slow booting of Debian, the inability to mount the drive, and the I/O errors, so it'd explain a lot.
Great. Well, I mean, bad, but that does narrow it down. So that drive is probably failing, but it can read from some places on the drive...just not all. And it fails pretty early, just a few KB into the partition. Though I don't know why you wouldn't get a kernel log message about that.
Well, if we're really lucky, maybe it just has a bad sector at that one critical location, and everything else is fine. Well, I'm not sure I'd trust a drive once it starts getting read failures, but point is that other data there might be readable. My understanding -- which dates to rotational drives -- is that normally hard drives maintain a map of sectors and a certain limited store of spare "good" sectors on the drive. When they write, if there's an error in writing, they switch to a "good" sector, mapping the location to that "good" sector so that, internally, every time you try to touch that location on the drive, the drive is actually using a different physical location. So even writing to that spot on the disk -- though I don't know if it's something that can be regenerated -- may cause the location to be readable again, because a drive will remap the sector to different physical underlying storage.
I understand that SSDs -- which are more free to remap sectors than rotational hard drives, for which it is expensive in time to send the head careening around the drive to weird, non-sequential sectors -- use something called "wear leveling", and regularly remap what's there, as they don't care about things being physically-contiguous and one can only write so many times to a given spot on an SSD, and this spreads out the places that are getting written to many times. So if one sector on an SSD starts failing, I'd be a little concerned about others going too.
So, a couple things that we can maybe experiment with. Maybe we start reading some distance into the drive, we can get some idea of what portion of the partition isn't readable.
ddis defaulting to reading in blocks of 512 bytes at a time. It manages to read 16 512-byte-size blocks into the partition, gets 8KiB of data, and then reading the 17th block is a problem. Maybe try:That'll skip over the first 1024 512-byte blocks -- that is, 512 KiB in), and start reading from that point. If the drive can't read from there, then you'll get an error, and if the drive can, then it'll read for at least a ways.
If the manual typing isn't a prohibitive problem with the CP, you can do a binary search for the end of the bad portion. So, we know that block 16 is good. We know that block 17 is bad. We don't know what extent of the partition the "bad" covers -- could be 1 block, could be the rest of the partition, could be an interspersed collection of failing and non-failing sectors. If it's just one short range, it might be possible to recover what's there.
So, I'd start at 1024. If dd can't read anything 1024 blocks in, then I'd double the "skip=" parameter to 2048, and try again. At some point, if you keep doubling the number, hopefully you'll get readable data (hopefully the rest of the partition). If it's readable, then cut in half the distance between the first-known "bad" block (currently 17) and the first-known "good" block. So, it'd look something like this, if hypothetically our bad range is 17-1500:
The commands there would be something like:
...etc. At some point, the first two numbers, the furthest-known "bad" and the first-known "good" will converge to a single block -- which for our hypothetical example, would be block 1500 -- and we know the end of the "bad" region (assuming that it is a contiguous bad region...we might skip over some good data).
I'd at least try a couple commands to get an idea of whether the whole disk is hosed or just a tiny portion at the start. If a lot of it isn't readable and can't be made to be readable, then it's going to be tough to recover. If it's a tiny amount of data at the beginning of the drive, that might not be so bad.
Maybe only try to copy a limited number of blocks each time, so ...for 5MiB, that'd be count=10240, so something like:
Then you don't have to whack Control-C to cancel it if most of the drive is "good" data.
If there isn't a whole lot of "bad" data, an option to try to pull all accessible data off the drive might be to try
ddrescue. In Debian, this is in the gddrescue package package. It will attempt to read from a block device, like your /dev/sdd1 partition, and write what it can read to another file or device. It'll retry places where it gets a read error, log where errors are in a "mapfile", and then move on to try to extract as much data from a device that is seeing hardware failures as possible. It's possible to try that. Unfortunately, I don't have a device that spits out read errors handy to try it out on, so I can only give you commands looking at the man page, can't test them out here. I also haven't used it before myself to recover data from a drive, since I haven't run into your "some of the drive is readable, some isn't" scenario. I believe that it used to be more-popular in the burned CD era, where sometimes similar problems would show up.You will also want to have a larger drive to be able to store the output from
ddrescueon. While I don't know whether reads will exacerbate problems for the SSD, for all I know, the drive might, as a whole, go belly up at some point, and reads might be an input into that, so it might be a good idea to, if the aim is to try to grab what can be grabbed from the drive, not do this a huge number of times.Another option would be to try to do the recovery directly on the problematic drive -- like, if only a small area is bad, it might be possible to write 0s or something to the bad range, hopefully make the area readable again, and hope that nothing in the bad region is critical for e2fsck to need to do the repair. If it's worth getting another drive to dump this onto first to you, though, and the existing drive doesn't have too much "bad" data, I'd probably do so and then try to repair the filesystem on that drive, as that would be less-intrusive to this drive, which I'd be inclined not to trust a whole lot. Worst case, it isn't repairable and then one has a new drive to store a new collection, I suppose.
sudo dd if=/dev/sdd1 status=progress skip=1024 of=/dev/null [sudo] password for mariah: 25847808 bytes (26 MB, 25 MiB) copied, 348 s, 74.2 kB/s dd: error reading '/dev/sdd1': Input/output error 50488+0 records in 50488+0 records out 25849856 bytes (26 MB, 25 MiB) copied, 355.279 s, 72.8 kB/s
Okay, well, that's not good in terms of being able to recover the data on the drive. So it's getting read errors from other positions on the drive, and this isn't right at the beginning.
thinks
Well, okay, two more things I'd try.
I'd try running the above command again, and seeing if it fails on the same block:
If on this run you again see it transferring 50488 512-byte blocks successfully and then failing on 50489, that means that it's the same locations failing each time. If so, that means that the errors are consistent at the same locations. That's bad in that there are multiple unreadable portions of the drive and you probably won't be able to read them, but at least it's possible to isolate those.
If not, if it fails at a different location, then maybe it's a sporadic problem. Ddrescue might be able to deal with that by just retrying reads on failure until it gets a good read. I doubt that this is the case, but I'd want to check, since it might permit for recovery of all of the data.
I don't know if this is typically the behavior seen when SSDs fail, as I came late to the SSD party and have only seen rotational drives fail; my own SSDs still work.
It failed at 50488
Gotcha, so the same spot.
Well, okay. So whatever is on the drive at failing locations is probably not going to be recoverable. It might still be possible to recover the bulk of the data on the drive, if the filesystem can br'e recovered.
I can't speak as to your financial situation or how much you care about that particular data.
First, it might be possible to hire a data recovery service to deal with it if you really care about it. I have no idea what, if anything, they can do with SSDs that are unreadable. With rotational drives, traditionally the problem was with the drive head, so they'd get a super-dust-free cleanroom, have duplicate hard drives of every model, open up your hard drive in the cleanroom and plop your platters and a fresh drive mechanism together, then pull the data off. That ran like a couple hundred to maybe two thousand bucks. Obviously, that's not applicable to SSDs, but there may be other things that they can do with them. I also don't know what they can do with Linux filesystems.
Second, if you get a new hard drive that is at least as large as the existing one, what can be done is to create a partition on that drive that is at least as large, use ddrescue to copy over what can be copied of the data on the partition and hope that it's enough for fsck to repair. Then, once you've got it working, if the new partition is larger, use resize2fs to grow the filesystem to the partition size. If it's not possible for fsck to repair it, then just stick a new filesystem on there, probably have to rebuild the music video collection from scratch if possible.
I can't promise that the existing data will be recoverable if you get the drive. Even if it is, it's possible that some music videos may have corrupt data, and it may be hard to easily identify which videos are corrupt. I hate advising people to spend their money, but I can't think of fantastic alternative approaches at this point; this is what I would do in your shoes at this point.
So that's gonna have to be a call that you're gonna have to make, as to whether you want to get a replacement drive. If you do, it's possible to try recovering the data.
If you pulled the music videos off YouTube -- I don't know where else one might have obtained thousands of them -- it may be possible to automate re-downloading them, at least the ones that are still on YouTube, using something like
yt-dlp. It may be possible to recover the filenames, even if the rest of the filesystem is unrecoverable, which might be used to search for the video. I'd do that via, after usingddrescueto try to pull as much data to the new partition as possible, runningstringson the new partition and searching it for filenames.So, your call. If you want to try recovery to a new drive, that's a possibility, but odds are that it won't be possible to recover everything perfectly-intact.
I don't think that there's a lot more that can be done without a new drive -- in theory, it'd be possible to try recovery on the existing drive, but given the state of it, I would guess that it could just wipe out what's there and still readable, and I'd advise not trying it. So at this point, this is probably blocked on you deciding whether you want to get and actually getting a new drive. If you do, it should be at least as large as the existing one, else it won't be possible to create a direct copy of the existing partition, which will be a pain for recovery purposes.
Of the other issues:
Boot time. I'd try my suggestion about disconnecting the external drive and seeing if your boot time problem goes away.
PATH. Setting PATH to include the /usr/local/sbin, /usr/sbin, and /sbin directories for non-root users should make those commands accessible to non-root users; I describe this in a top-level comment. Alternatively, just running
su -lshould give you a root shell with a PATH that includes those directories under Debian. I know what has to be done, but not the appropriate place to set it every login for the current desktop environments, as I don't use them.sudo rights to your user account. As long as you have added your user to the sudo group and logged them out and logged in again, you should be good to go here; I assume that this is working now.
Distro. I am inclined to believe that there was likely not anything wrong with your Arch installation other then the failing drive, from what you've told us. I'm not going to dissuade you from using Debian -- I mean, it's what I use -- but if that was all you were concerned about with Arch, you could probably reinstall it if you were otherwise happy with it and don't mind doing the reinstall. I can't help much there, though, as I've never installed Arch.
I have decided to just unplug the sdd. I have fixed the path issue by adding my user to sudo. Ill stick to debian as im not a hopper. Thanks for helping me
No prob. Hope things go more-smoothly in the future with the machine.