this post was submitted on 22 Sep 2025
1126 points (99.1% liked)
Microblog Memes
9356 readers
2337 users here now
A place to share screenshots of Microblog posts, whether from Mastodon, tumblr, ~~Twitter~~ X, KBin, Threads or elsewhere.
Created as an evolution of White People Twitter and other tweet-capture subreddits.
Rules:
- Please put at least one word relevant to the post in the post title.
- Be nice.
- No advertising, brand promotion or guerilla marketing.
- Posters are encouraged to link to the toot or tweet etc in the description of posts.
Related communities:
founded 2 years ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
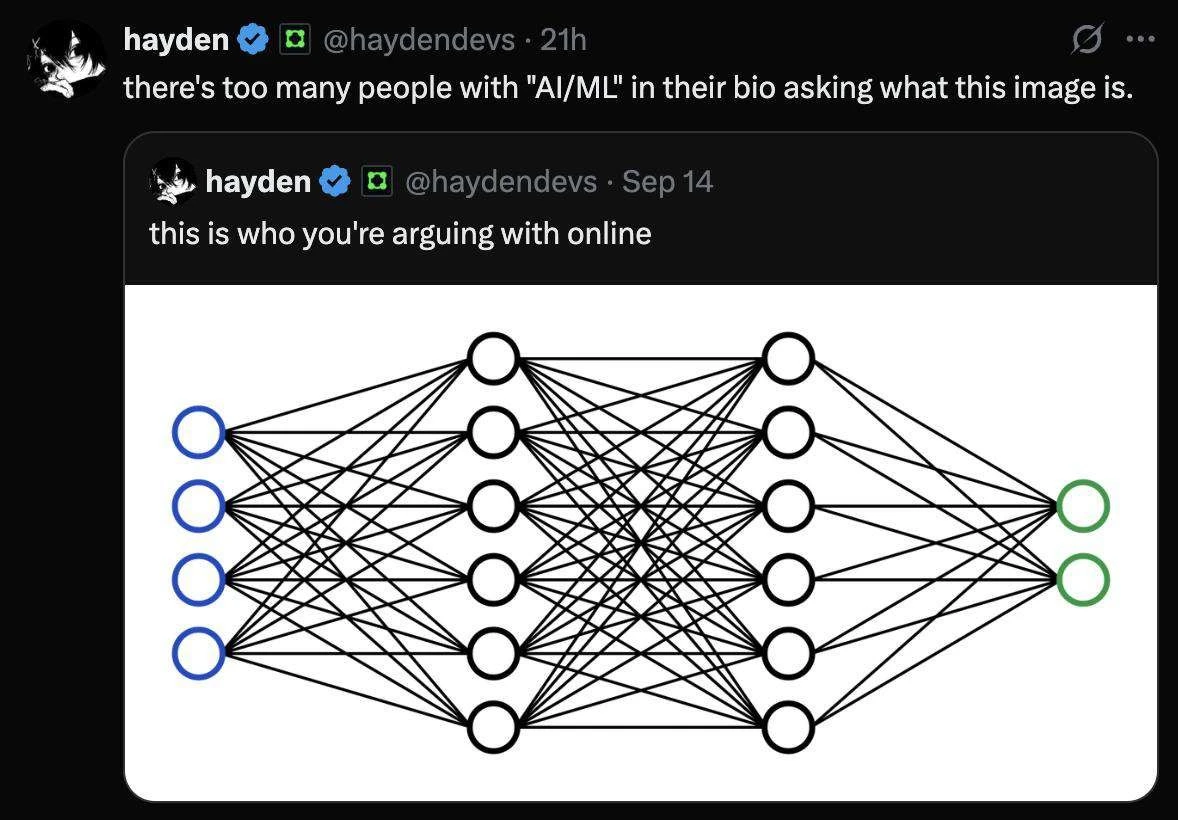
In practice it's very systematic for small networks. You perform a search over a range of values until you find what works. We know the optimisation gets harder the deeper a network is so you probably won't go over 3 hidden layers on tabular data (although if you really care about performance on tabular data you would use something that wasn't a neural network).
But yes, fundamentally, it's arbitrary. For each dataset a different architecture might work better, and no one has a good strategy for picking it.
There are ways to estimate a little more accurately, but the amount of fine tuning that is guesswork and brute force searching is too damn high...